In Spring of 2025, researchers at the AI company Anthropic released a pair of papers in which they document a method for making the internal workings of a large language model like Claude interpretable rather than a mysterious black box. They also provide many case studies where they are able to probe the inner workings of Claude during tasks like multi-step reasoning, planning while composing poetry, pursuing secret goals, generalizing from specifics to a general rule, and reported vs. actual mechanisms during chain-of-thought reasoning reporting. Below I provide some background on the idea of making neural networks — whether human or artificial — interpretable in a way that we can understand mechanistically what they are doing ‘under the hood’.
Cognitive models: Human memory and concept representation
In the middle of the 20th century, behaviorism was one of the most dominant paradigms for studying and understanding the psychology of humans (and other animals). Behaviorism is often described as a science of psychology that ignores internal mental states and focuses exclusively on observable behaviors. The environment provides an input and the organism (human or animal) performs a behavior as an output, and what happens in the middle — in the head, in the mind — is an impenetrable black box. This philosophy is said to treat behavior as a natural science like chemistry and biology, predictable causal rules discovered with experimental analysis of environment inputs and behavioral outputs, all without needing to refer to inner, mental states1.
In the latter half of the 20th century, the cognitive revolution and development of cognitive science largely pushed behaviorism out of favor. In its place cognitive psychology became perhaps the most dominant approach for studying the mind, and from the start cognitive psychology had no compunctions about theorizing what’s happening inside the head, what’s happening in that black box. Cognitive psychologists develop models of mental processes like attention, language use, memory, perception, problem solving, and reasoning that are meant to at least approximate how those processes actually function.
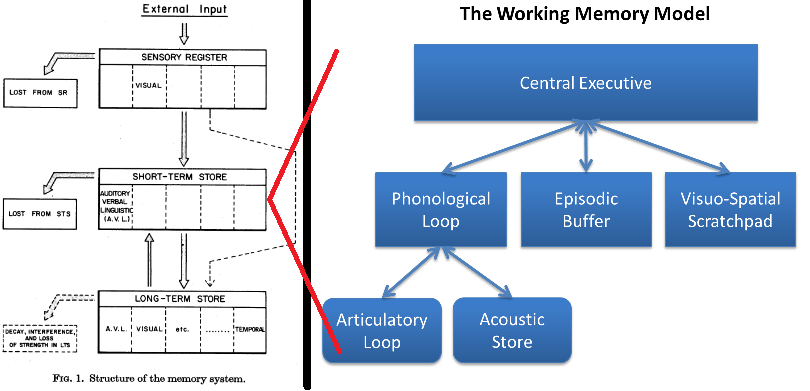
Take a classic example: Atkinson and Shiffrin (1968) modeled memory as having three interacting parts: a brief sensory memory for everything coming in to our brain from our sensory organs, some fraction of which gets transferred to short-term memory (where you hold a phone number in your head, for example), and then, depending on encoding processes, some of that gets laid down in long-term memory, retrievable much later. Years later, the part we called short-term memory was updated to a new model based on myriad experimental results: working memory, seen less as a short-term storage register and more as a multi-component model itself, a system of processes where we actively manipulate information. For example, when solving 24 + x = 53 – 2, we hold the input numbers and intermediate values in mind while also planning and conducting operations like addition and subtraction.
{kind=link}
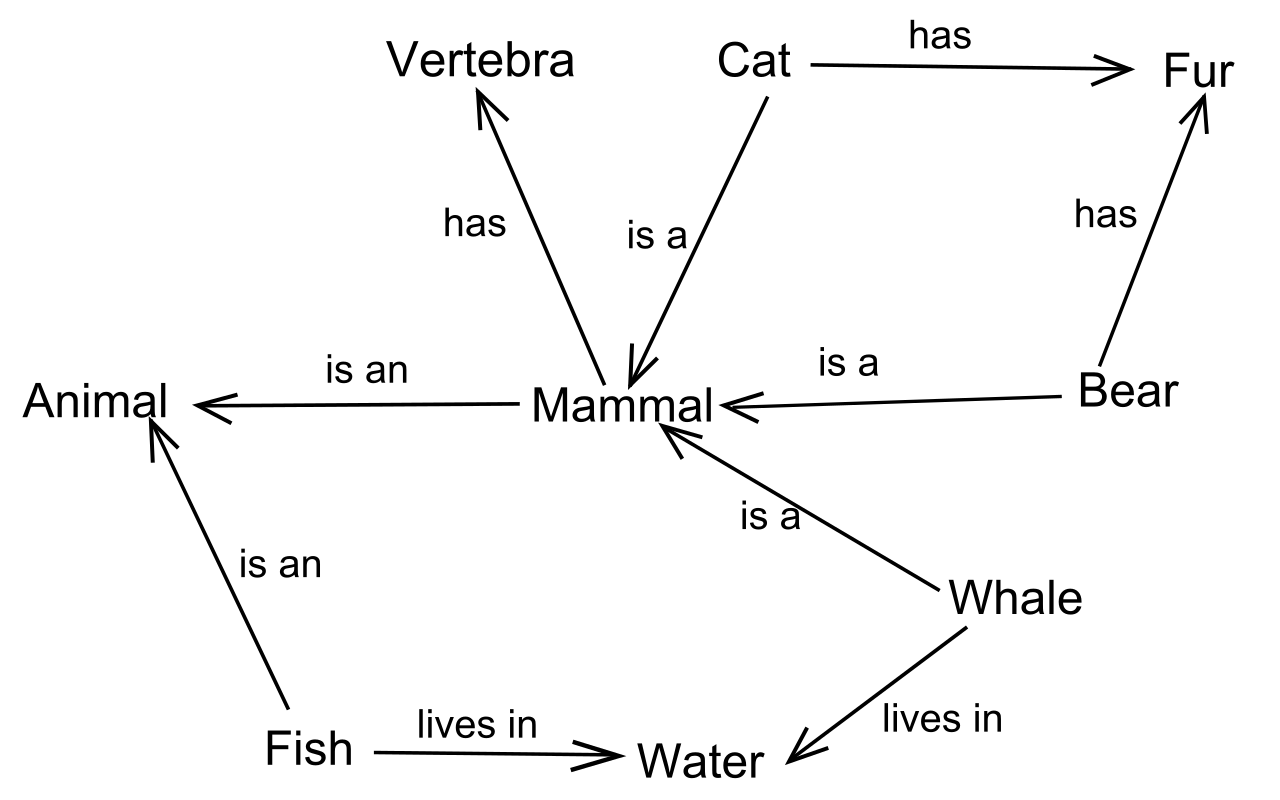
Likewise, cognitive psychologists use a semantic network model to represent how concepts are stored, connected, accessed, and updated across the complex networks of neurons in our brain. For example, a cat is a mammal and a mammal is an animal, but cat doesn’t have the “is a“ relationship with fish. Concepts are modeled as being more closely connected in the network to closely-related concepts than to distantly-related or unrelated concepts. That is to say, ideas that are closely associated in meaning and usage (like “school bus” and “yellow”) co-activate more often in our experience than ideas that are less associated (like “school bus” and “purple”), so purple would be shown at a further distance in our semantic network model.
{kind=link}
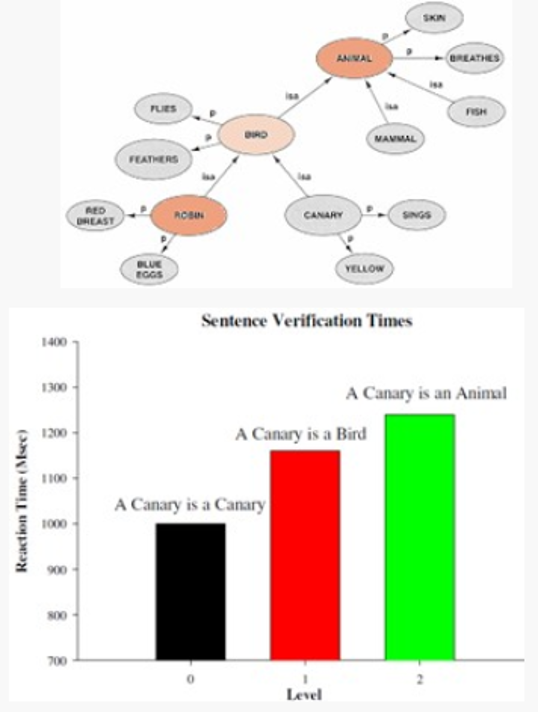
From this, cognitive psychologists developed models like spreading activation to understand and represent what is happening when we activate a concept, i.e. when we think about it and activate its neural representation (Collins & Loftus, 1975). The idea is that activating a node in our semantic network — thinking about a concept — doesn’t just activate the node itself but also adds some activation to the nearby nodes (and then less to some nodes a little further away, and so on). This can explain why our brain is faster to recognize that a cardinal is a bird than to recognize that a cardinal is an animal (the spreading activation meets earlier and more strongly in the former case than the latter). It also explains why we’re more likely to fill in the blank “S O_ _” as soup if we’re primed to think about food first but as soap if we’re primed to think about cleaning first or song if we’re primed to think about music first.
Models like this of cognitive functions such as memory and knowledge representation are imperfect, as all models are, but what they are is an attempt to approximate the actual structures and mechanisms underlying cognition. They provide a high-level starting point from which experiments can be designed to probe and test the specifics, leading to updated versions of the model that over time more closely resemble the real process that’s being modeled. They let us peek inside the black box to better understand what’s happening in our heads2.
Artificial intelligence as a black box
Large language models (LLMs) like OpenAI’s ChatGPT, Google’s Gemini, and Anthropic’s Claude have been in the news regularly since late 2022 when ChatGPT’s public release became what was described as the fastest growing consumer app in history (though of course the story leading up to ChatGPT’s public release goes back much earlier). The most popular LLMs are generative pretrained transformers (GPTs) which use what’s called transformer architecture (the T in “GPT”) where multilayer perceptrons are combined with an attention mechanism (Vaswani et al., 2017).
In a sense, we understand what LLMs are doing; the algorithms by which they are trained and by which they run are well understood3. My favorite explainer is a short series by YouTuber 3Blue1Brown: in 2.5 hours you can come away with a pretty decent understanding of the nuts and bolts of generative pretrained transformer models like ChatGPT.
Like all computers these systems are deterministic, meaning the same input will produce the same output every time. Yet despite that fact — and despite comprehending the algorithms underlying GPT design — these systems are consistently doing things and producing output that, in practice at least, we can’t predict. We genuinely don’t fully understand how these models are accomplishing what they are, despite knowing the computational architecture that powers it.
Certainly, a deterministic system made up of simple parts can give rise to emergent behavior, just as the complex interactions of many ants or termites can give rise to impressively complex architectural and design feats that no individual insect understands. Individual neurons in our brain don’t think or reason at any meaningful level, but the complex interplay of tens of billions of them allows us to write poems, develop calculus, and imagine unicorns. And it seems that artificial neural networks (like the transformer architecture of an LLM), despite being made of simple parts manipulated by simple mathematical operations, can give rise to very complex outputs in ways that are hard for us to predict.
When it works, it feels a little like magic. These machines aren’t thinking, we’re reminded; they’re just generating the statistically most likely next word-like token, so how the hell can they output convincing poetry and persuasive essays or solve complex math problems so effectively? Can we find ways to better understand what is happening inside black box AI?
Starting to penetrate the black box: semantic embeddings
How do we better understand what’s going on in the hidden layers of a LLM neural network? One way is to look at how meaning is embedded within the system. In other words, how does a neural network represent a concept like, say, “science” or “river” or “king”? (Note that in AI research, these concepts are called features).
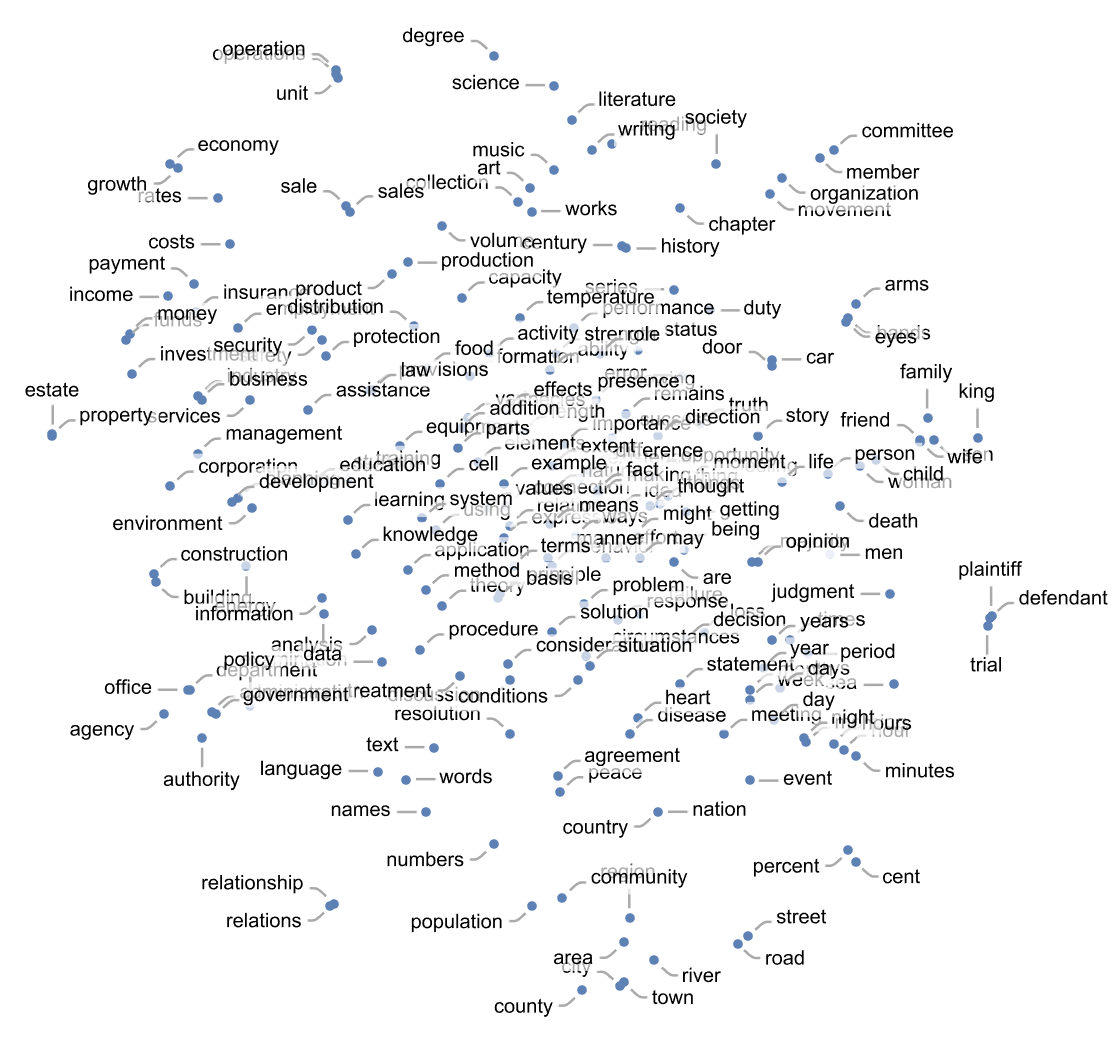
We know that text in an LLM is basically represented by a vector of numbers which are in essence coordinates in an n-dimensional linguistic feature space. We can even project this feature space down to 2 dimensions and immediately see some interesting patterns: for example, the numerical representation of common nouns shows some of them closer to each other than others. For example, as you can see below the vector of numbers representing “plaintiff” is very similar to that representing “defendant” and much more dissimilar to the vector of numbers representing “art” or “construction” (Wolfram, 2023).
Furthermore, the distance between vectors representing words seems to embed meaningful relationships. For example, when we probe the feature space for the distance between the vector representations of, say, ‘finger’ and ‘hand’, we find a very similar distance and direction in that feature space between ‘toe’ and ‘foot’, implying a sort of embedding of analogy or the concept of being a digit on a limb’s effector (Wolfram, 2023).
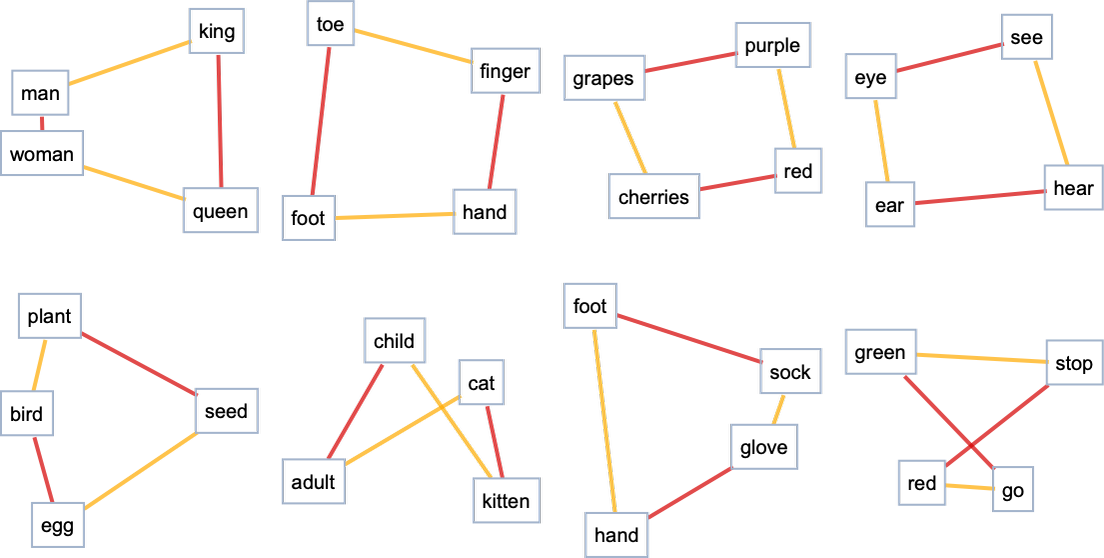
So we’re able to probe the system and get a feeling for one way that it seems to be encoding (representing?) semantic meaning. We can also probe and visualize similar meaningful embeddings within other neural networks such as image recognition systems.
Representing simple features and high-level features: The case of AlexNet
As Welch Labs explains in this beautifully-visualized short YouTube video (18 mins), all a system like ChatGPT is doing at its most fundamental level is taking in a vector of numbers embedding a chunk of text, performing some matrix algebra, and then outputting a vector of numbers that represents the next bit [token] of text. We understand the fundamental steps of the algorithm underneath something like ChatGPT, yet we’re now far past the point of fully understanding exactly how those operations are allowing the higher-level performance we see on tasks we long thought exclusively human.
The video points to developments in 2012 as the tipping point when we moved from AI solving tasks with human-designed algorithms to neural network approaches where the task solutions almost bubble up from a form of learning (tuning the neural network with a huge amount of data). Specifically, 2012 was when the famous AlexNet paper achieved image recognition feats in ways that stretched our ability to easily interpret what’s going on inside (Krizhevsky et al., 2012).
AlexNet used what’s called convolutional neural network architecture, as is common for computer vision tasks. In this case, you input an image as a vector of numbers — rather than a piece of text as a vector of numbers — and the system outputs a vector of numbers representing probabilities for various possible linguistic labels for that image.
When probing what the initial inner layer of the AlexNet model is doing, we can see in section 5 of the paper that the model seems to be representing edges (areas of contrast from light to dark) and color blobs in this first layer, which is remarkably similar to how our own early visual processing works. In human brains, the primary visual cortex where early visual processing happens is full of what we call “simple cells”, neurons that fire if and only if there is an edge (a line of contrast) of a particular orientation in one particular part of our visual field. See my lecture on simple cells for more explanation. Likewise, our primary visual cortex has ‘blobs‘ of neurons sensitive to color information.

From these simple building blocks, our brain is able recognize more complex combinations of simple parts. For example, we can recognize corners as a combination of two edges at a particular angle. Indeed, in the primary visual cortex we find neurons that fire specifically for corners (a specific combination of edges) at a particular part of the visual field, or neurons that fire specifically for moving edges and moving corners in a given part of the visual field. (I explain this more thoroughly in my lecture on complex cells and encoding in early visual cortex).
Then from combinations of all these simple bits, we can start to recognize more complex features (combinations of simple features) that make up everyday patterns like faces, chairs, and tigers. And as the Welch Labs video shows, by the second layer of AlexNet, it seems to be representing somewhat higher-level features like corners.

The video continues: “Remarkably, as we move deeper into AlexNet, strong activations correspond to higher- and higher-level concepts. By the time we reach the fifth layer, we have activation maps that respond very strongly to faces and other high-level concepts.”
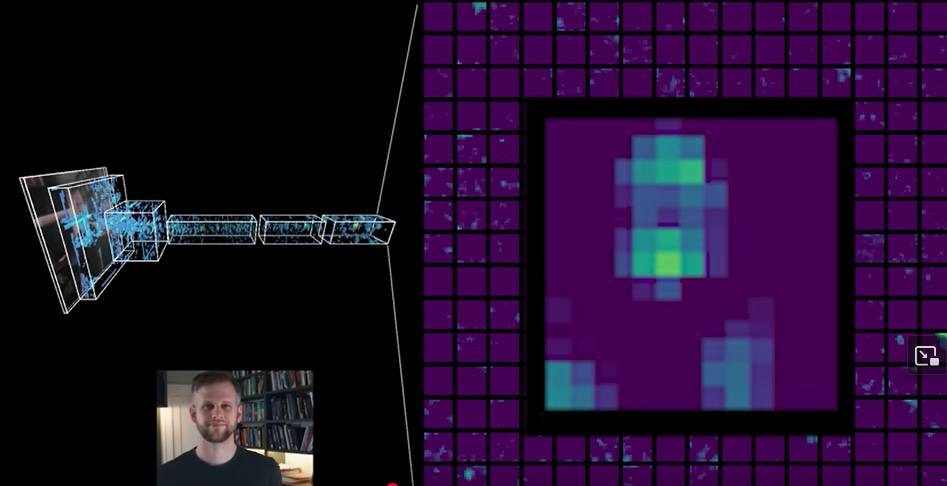
“And what’s incredible here,” the video continues, “is that no one explicitly told AlexNet what a face is. All AlexNet had to learn from were the images and labels in the ImageNet dataset which does not contain a person or a face class. AlexNet was able to learn completely on its own both that faces are important and how to recognize them.”
By the time we get to the second-to-last layer of AlexNet, we’re just dealing with a vector of numbers (as shown in the final step on the right in the image below).

These vectors of numbers are basically representing things in a high-dimensional space, but we can compute the distance between two such vectors to see how close or far these next-to-last-layer representations are for different images (e.g., how far the dog image’s next-to-last-layer vector is from the ship image’s next-to-last-layer vector).
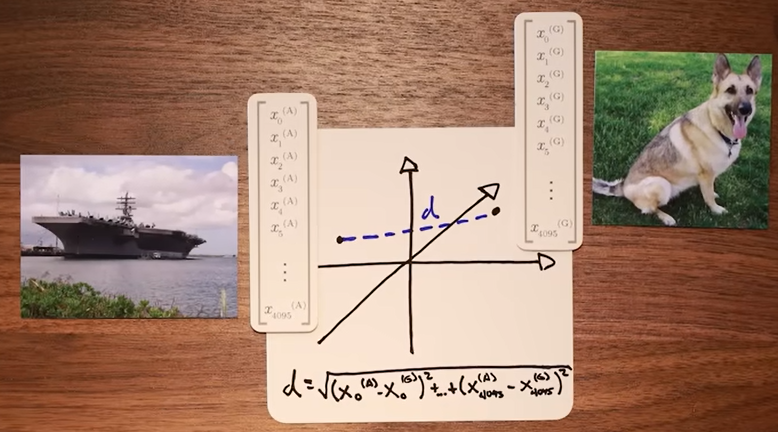
What the AlexNet authors found was that images of similar things were embedded nearby in this n-dimensional space, even if their individual pixels were incredibly different. For example, when picking out a random image from the training set (an elephant, for example), they looked at the vector AlexNet produced in the next-to-last layer when fed in that elephant image. Then they looked at which images in the huge dataset happened to produce a vector (for their own next-to-last layer when passed through AlexNet) with the smallest distance from this target image. And sure enough, the images closest in this n-dimensional next-to-last-layer space were of objects similar to the test image’s object. The next-to-last layer for one elephant image was very similar to the next-to-last layer for other elephant images (i.e. relatively small distance between them in n-dimensional space4).

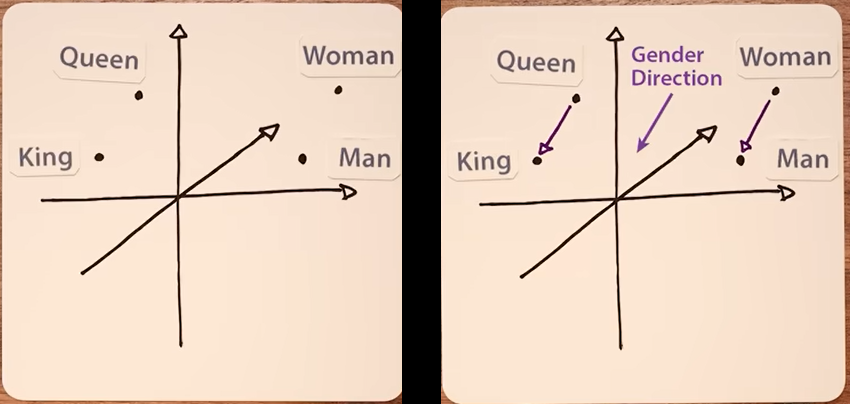
This is similar to what we saw before with large language models. In LLMs like ChatGPT, words (or word fragment tokens) are mapped to vectors of numbers in an n-dimensional embedding space. And in that space, words with similar meanings are embedded close to each other, as seen in the common example below where man is close to woman, and similarly queen is close to king. Indeed, the direction/distance between woman and man in that embedding space is very similar to the direction/distance between queen and king (in other words, that direction/distance seems to embed gender).
AI interpretability
These attempts to probe inside an artificial neural network to better understand how it is representing and manipulating information falls under the field of AI interpretability (sometimes called mechanistic interpretability). Interpretable AI means articulating what a system is doing under the hood in a way that is understandable by humans, comprehending not just its architecture but how it is doing what it does. (This is related to but distinct from what’s called explainable AI which is more like a system being able to give the reasons for its output or decision, regardless of the mechanistic inner workings).
Interpretability has been of interest in modern AI systems for a while now. For example, in 2018 researchers at Google Brain published a famous paper on the building blocks of interpretability showing how interpretability methods like feature visualization, attribution, and dimensionality reduction could be combined to systematically probe neural networks in interpretable ways (Olah et al., 2018).
That paper has some lovely interactivity giving the reader an intuitive feel for some of the ways we might probe neural nets at a human-interpretable level. For example, you can point at any part of an image and get not just the numerical vector of activation of individual neurons, spaces, or channels in a given hidden layer of the network, but see the activation of various feature detectors: for example, when probing an image of a puppy and cat, you can see that the network seems to have feature detectors specific to things like floppy ears, dog snouts, cat heads, and so on! These aren’t detecting features in terms of linguistic labels, but visual regularities, hence one feature detector might “fire” (akin to neural firing in a brain) for floppy ears of a particular length or color while another might fire for another type of floppy ears, and others for features we have no linguistic category for at all.

As the authors say, “by working across [hidden] layers […], we can observe how the network’s understanding evolves: from detecting edges in earlier layers, to more sophisticated shapes and object parts in the latter.”

In addition to feature detection, they discuss attribution which is identifying which parts of a model contributed most to the final output or decision. For example, a neural network might classify the above image as having a puppy in it, and an attribution map would show us which parts of the input image (or which features the model has learned) contributed most to that decision.
Early and simplistic methods of attribution include things like salience maps which detect which pixels in the input image contributed most to the final classification as a puppy. But applying attribution not to individual pixels of the image but to deeper representations within the hidden layers of the network allows much more powerful attribution.
As they say, “[w]e instead treat attribution as another user interface building block, and apply it to the hidden layers of a neural network. In doing so, we change the questions we can pose. Rather than asking whether the color of a particular pixel was important for the ‘labrador retriever’ classification, we instead ask whether the high-level idea detected at that position (such as ‘floppy ear’) was important.”
Olah and colleagues move the focus from individual neurons (of which there are too many for a human to interpret meaningfully) to groupings of neurons that fire together in a correlated way, meaning these neural groupings can be treated as a sort of unit of analysis. There are different ways to do this grouping — various methods of matrix factorization that maximize different goals and thus have different tradeoffs — but they show how this can simplify the interpretability task to stay at more human-digestible levels.
In the image below, you can see what it looks like when factoring to, say, 6 neural groupings within a particular network layer. Below that are displayed the corresponding feature visualizations connected to each grouping. So the blue neural groupings seem to be picking up dog faces, the green neural grouping seems to be picking up floppy ears, and the pink grouping seems to be a set of neurons that detects small four-legged bodies, or something close to that. The interface in the Olah et al. (2018) paper allows you to see what happens if you factor to 4 groupings of neurons, or just 2, or 10 — again, I love the interactivity of this paper.
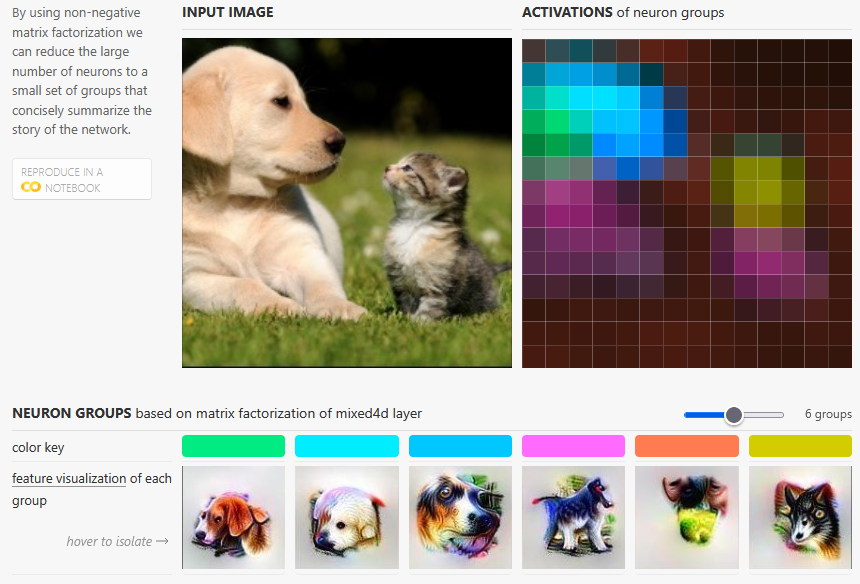
As they explain, different combinations of interpretability methods like feature detection, attribution, and dimensionality reduction can be applied to different layers of a neural network, focusing on different units of analysis (from individual neurons to groups of neurons), and visualized or presented in different ways in order to answer different interpretability questions. In essence, they are laying out a grammar for interpretability research on a neural network, different ways of combining methods to get a better (and human-level) understanding of what is actually going on in those hidden, black box layers.
More recent mechanistic interpretability in LLMs
Olah et al. (2018) end their paper on the building blocks of interpretability by pointing out that this kind of interface for understanding a neural network’s inner workings is only trustworthy if the neurons (or groups of neurons) actually have consistently meaning across different inputs (e.g., the floppy ear detector grouping always works as a floppy ear detector grouping, so to speak). And this seems to be the case for much of what we find in neural networks: the authors give the familiar example of semantic arithmetic (where the vector representation of “king” minus that of “man” plus that of “woman” equals “queen”).
Neural networks do seem to embed semantic meaning, but one issue we run into is monosemanticity vs. polysemanticity. A monosemantic neuron would be one that represents one specific meaning, like “cat” (firing specifically to cats, but not other things). On the other hand, a polysemantic neuron would be one that fires to different things (like cats and cars).
Given that many individual neurons in a neural network are polysemantic, they don’t provide the best unit for natural human understanding. And one reason we might end up with polysemanticity is what’s called superposition: a neural network might encode or represent more features (more meanings, so to speak) than it has individual neurons by representing features using combinations of neurons.
This idea should be familiar to anyone who has studied human and animal neuroscience! As I explain in one of the YouTube lectures from my sensation & perception course, our own brains sometimes use specificity encoding (an individual neuron encoding something), and other times use population coding (a pattern of firing across a huge group of neurons encoding something), but for many processes our brain uses sparse coding (a pattern of firing across a relatively small population of neurons encoding something)5.
So superposition is one cause of polysemanticity where a neuron firing may not have a simple meaning, but may be part of many distinct combinations of neurons that represent different meanings (features, in neural network lingo). And in recent years, researchers have been trying to identify feature representations that may be hidden across the combination of a relatively sparse number of neurons. One of the big breakthroughs was in 2023 when Bricken et al. at Anthropic presented an algorithm called a sparse autoencoder that “generated learned features from a trained model that offer a more monosemantic unit of analysis than the model’s neurons themselves.”
Their paper, which you can dive into here, applies this sparse autoencoder technique to pull out interpretable features from a transformer architecture neural network. In this case, a simplified version, a one-layer transformer with a multilayer perceptron (MLP) layer — what they describe as “the simplest language model we profoundly don’t understand”. Their technique allows decomposing activations of the MLP into many more features than there are neurons in the MLP itself. By using this method, they can extract features that are “significantly more monosemantic than neurons”. A feature might be Hebrew script or Arabic script or DNA sequences, say, and they are able to pull out these learned features in ways that are specific (i.e. only fire for Hebrew), sensitive (i.e. do fire if there is Hebrew), causal in downstream model behavior, but doesn’t correspond to any individual neuron.
Since then, the same group has built upon that work and in 2024 published a really intriguing paper “Scaling monosemanticity: Extracting interpretable features from Claude 3 Sonnet” (Templeton et al., 2024). Here they moved from a simplistic toy model (one-layer transformer) to a modern LLM (Claude 3 Sonnet), and found that the sparse autoencoder technique is able to extract abstract features like famous people, countries and cities, and so on — and that these features (what we might think of as concepts) are in some cases multilingual (activating for the same concept regardless of language) and multimodal (activating for the same concept whether it shows up in text or visually).
They point out many interesting patterns, like features becoming less specific as activation strength weakens. “This could be due to the model using activation strengths to represent confidence in a concept being present. Or it may be that the feature activates most strongly for central examples of the feature, but weakly for related ideas – for example, the Golden Gate Bridge feature 34M/31164353 appears to weakly activate for other San Francisco landmarks.” They consider other explanations as well, but “[n]onetheless, we often find that lower activations tend to maintain some specificity to our interpretations, including related concepts or generalizations of the core feature. As an illustrative example, weak activations of the transit infrastructure feature 1M/3 include procedural mechanics instructions describing which through-holes to use for particular parts.”
They’re even able to identify features within Claude 3 Sonnet that appear to correspond to concepts like gender bias, racism, and hatred, or concepts like sycophancy (sycophantic praise, ‘yeah me too’ empathy), or even concepts around deception, manipulation, and secrecy. Indeed, these features seem to relate to Claude’s behavior (outputs): when they ramp up the so-called “secrecy and discreteness” feature, Claude says one thing to the user in its ‘thinking out loud’ scratchpad while actually intending to lie to the user.

There are tons of limitations and caveats in this work, but it’s intriguing to see these early attempts to probe fairly state-of-the-art LLMs for meaning representation in terms of human-interpretable features. It’s hard not to think of these models as activating concepts in a way analogous to how our own brains activate concepts (and, in doing so, weakly activate neighboring concepts in our own semantic map space).
They end the paper by raising questions for future study about when features — including those relevant to AI safety — might activate. In other words, the model may have a ‘concept’ of lying or even of fictional AI entities that take over the world, but what kind of inputs to the model will activate these features? What kinds of activations might lead to the model giving instructions for, say, making biological weapons? These are just some of the applications that might help convince policymakers and others of the importance of AI interpretability, if indeed the methods this team is employing are capturing genuine and causal model features (as they argue).
And now, in late March of 2025, the same research team at Anthropic has released a pair of papers where they further develop these methods to make the internal workings of an LLM like Claude interpretable rather than a black box.
The first paper documents the methods they’ve developed allowing them to get more interpretable components out of an underlying model by, in essence, setting up a parallel “replacement model” that traces the original model’s computations in an understandable way that can be visualized and validated. In this case, they use a transcoder technique rather than sparse autoencoders, and doing so allows analysis of how features interact with each other. Once again they are able to tease out features that are fairly straightforward for humans to recognize and interpret (those at the input and output layers, especially) such as a feature that seems to selectively activate for the word “digital” or variations like “digitize” or a feature that seems to selectively activate for the tokens relating to six (e.g., “6”, “six”, “June”, tokens ending in “6”). They also extract features from the middle (hidden) layers of the model that are more abstract, like activating selectively for acronyms where “D” is the second letter in the acronym (e.g., ADT, DDT, CDS).
But the real exciting thing in that first paper is how their method allows circuit tracing — that is to say tracing computational steps through the model — and that is where things get super cool when applied to a live production LLM (Claude 3.5 Haiku) in the second paper to mechanistically probe what it’s doing inside. They use their method to trace the inner workings of Claude in a variety of contexts such as:
- Multi-step reasoning (e.g., identifying that the capital of the state containing Dallas is Austin)
- Planning in poetry (e.g., identifying potential end-line rhyming words before beginning to write a line)
- Medical diagnoses (e.g., identifying candidate diagnoses and then developing follow-up questions from those)
- When jailbroken (e.g., when the model is tricked into giving dangerous instructions “without realizing it”)
- Chain-of-thought reasoning (e.g., in what cases does the model actual perform the steps it says it is performing versus making up its reasoning)
Frankly, this work is incredibly interesting! It’s just one method — one tool — for probing models to get at mechanistic interpretability, and the researchers don’t hesitate to point out limitations and places where their assumptions may turn out wrong. Regardless whether these specific methods end up being the most useful or not — or even if the theoretical assumptions of polysemanticity and superposition turn out not-quite-right — this type of work is what will allow us to get some grasp on what AI systems are doing, similar to how cognitive models and neuroscientific techniques have allowed us to begin peaking into the black box of our own minds.
I’m skeptical that interpretability will be the key to AI safety as these models further evolve (Neel Nanda from Google DeepMind argued something similar recently), but (1) it’s certainly likely to be one helpful tool in that battle6, and (2) I just find it so cool and fun from a basic science perspective of understanding how cognition happens in different systems (humans, non-human animals, and perhaps even AI).
Footnotes
1 Of course, that over-simplification does a disservice to the most famous version of behaviorism developed by B.F. Skinner: radical behaviorism. Radical behaviorism doesn’t deny the role of thoughts and feelings in understanding behavior, but treats these “private events” as, in essence, behaviors themselves. These private, internal behaviors are part of the same processes of operant and classical conditioning as our more overt and observable behaviors like raising our hand, pulling a lever, or smiling; but given that they are not directly observable, Skinner considered private events outside the reach of direct analysis.
2 Another great example is the pandemonium model and feature integration theory of perception which aligns quite nicely with experimental neuroscience evidence of how early visual perception allows us to recognize stimuli. See my YouTube lecture on that topic for more info. It sure looks a lot like, say, Google Brain’s 2018 attempt [non-paywall link] to model what an artificial neural network is doing when it recognizes an image of an object.
3 That may change when AI models start developing the code for newer AI models.
4 In this case, by distance we really mean distance and direction in n-dimensional space.
5 I give additional examples from gustatory neuroscience around the 24 minute mark in this lecture video on taste perception.
6 In April Dario Amodei (CEO of Anthropic) also had some interesting things to say on interpretability relating to this.
References
Atkinson, R. C. & Shiffrin, R. M. (1968). Human memory: A proposed system and its control processes. Psychology of Learning and Motivation, 2, 89-195. https://doi.org/10.1016/S0079-7421(08)60422-3 [PDF]
Baddeley, A. (2000). The episodic buffer: A new component of working memory? Trends in Cognitive Science, 4(11), 417-423. https://doi.org/10.1016/s1364-6613(00)01538-2
Baddeley, A., & Hitch, G. (1974). Working memory. Psychology of Learning and Motivation, 8, 47-89. https://doi.org/10.1016/S0079-7421(08)60452-1
Bricken, T., Templeton, A., Batson, J., Chen, B., Jermyn, A., Conerly, T., Turner, N. L., Anil, C., Denison, C., Askell, A., Lasenby, R., Wu, Yifan, Kravec, S., Schiefer, N., Maxwell, T., Joseph, N., Tamkin, A., Nguyen, K., McLean, B., Burke, J. E., Hume, T., Carter, S., Henghan, T., & Olah, C. (2023, October 4). Towards monosemanticity: Decomposing language models with dictionary learning. Anthropic Transformer Circuits Thread. https://transformer-circuits.pub/2023/monosemantic-features/index.html
Collins, A. M., & Loftus, E. F. (1975). A spreading-activation theory of semantic processing. Psychological Review, 82(6), 407-428. https://doi.org/10.1037/0033-295X.82.6.407
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet classification with deep convolutional neural networks. Proceedings of the 26th International Conference on Neural Information Processing Systems, 1, 1097-1105. https://dl.acm.org/doi/10.5555/2999134.2999257 [PDF]
Olah, C., Satyanarayan, A., Johnson, I., Carter, S., Schubert, L., Ye, K., & Mordvintsev, A. (2018). The building blocks of interpretability. Distill. https://doi.org/10.23915/distill.00010
Templeton, A., Conerly, T., Marcus, J., Lindsey, J., Bricken, T., Chen, B., Pearce, A., Citro, C., Ameisen, E., Jones, A., Cunningham, H., Turner, N. L., McDougall, C., MacDiarmid, M., Tamkin, A., Durmus, E., Hume, T., Mosconi, F., Freeman, C. D., Sumers, T. R., Rees, E., Batson, J., Jermyn, A., Carter, S., Olah, C., & Henighan, T. (2024, May 21). Scaling monosemanticity: Extracting interpretable features from Claude 3 Sonnet. Anthropic Transformer Circuits Thread. https://transformer-circuits.pub/2024/scaling-monosemanticity
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention is all you need. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan and R. Garnett (Eds.), 31st Conference on Neural Information Processing Systems (NIPS). Curran Associates, Inc. https://doi.org/10.48550/arXiv.1706.03762 [PDF]
Wolfram, S. (2023, February 14). What is ChatGPT doing…and why does it work? Stephan Wolfram Writings. https://writings.stephenwolfram.com/2023/02/what-is-chatgpt-doing-and-why-does-it-work/
Leave a Reply